
Im Themenbereich Datenmanagement werden Anwender und Entscheider immer wieder mit neuen Begrifflichkeiten konfrontiert. Eine davon ist „Data Wrangling“.
Mein folgender Beitrag soll darüber informieren, was sich hinter diesem Begriff verbirgt und im Folgenden das Tool präsentieren, welches in seiner Selbstdarstellung explizit mit diesen Begriff wirbt: Den Trifacta Wrangler.
Was ist Data Wrangling?
Unter Data Wrangling verstehe ich den manuellen bzw. teilautomatisierbaren Prozess der Aufbereitung und dem Anreichern von Rohdaten zum Zwecke der darauf folgenden Analyse und Visualisierung.
Ein solcher Data Wrangling-Prozess besteht aus mehreren Teilschritten:
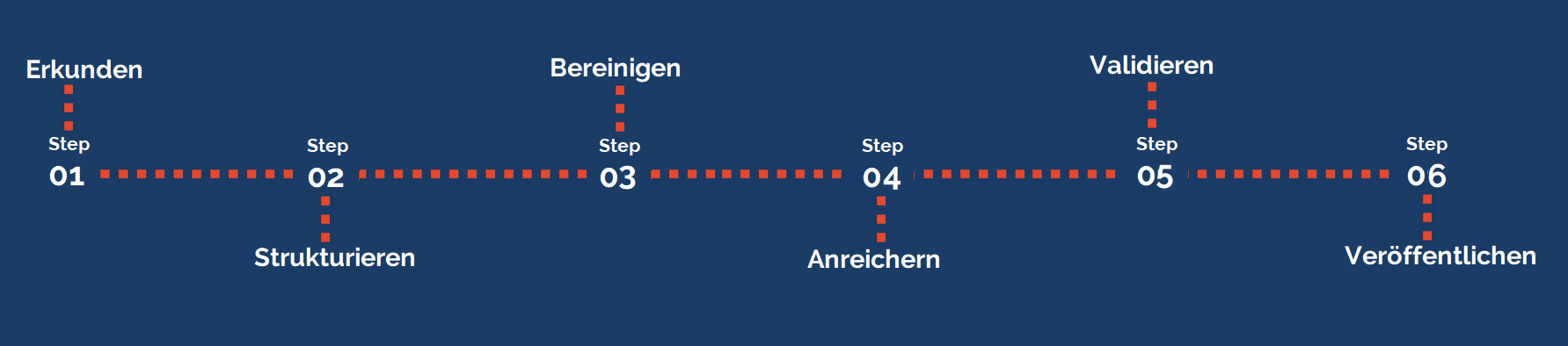
- Erkunden: Im ersten Schritt möchte ich Verständnis gewinnen, wie meine Daten überhaupt strukturiert sind und woher sie kommen?
- Strukturieren: In diesem Schritt werden die Daten einheitlich umstrukturiert, so dass ich sie für die Analyse verwenden kann. Dazu kann beispielsweise das Weglassen oder Erzeugen neuer Spalten durch das Auseinandertrennen oder Extrahieren von Werten sein.
- Bereinigen: Dieser Schritt soll beispielsweise durch die Behandlung von nicht plausiblen Werten oder Leerzeichen die Datenqualität erhöhen.
- Anreichern: Hier geht es darum, den vorhandenen Daten weitere Daten aus anderen Quellen hinzuzufügen oder neue Spalten aus bereits vorhandenen Daten über Berechnungsvorschriften abzuleiten.
- Validieren: Über Validierungsregel werden die Daten überprüft um Inkonsistenzen zu erkennen und dadurch eine hohe Datenqualität zu sichern.
- Veröffentlichen: Hier handelt es sich um den Prozessschritt, der sich damit auseinandersetzt, wie die bearbeiteten Daten in der Folge den fachlichen Analysten in welchen Anwendungen bereitgestellt werden.
Ein solcher Prozess wird schon seit längerem in der Literatur als „Data Preparation“ bezeichnet. Teilweise werden die Begriffe auch synonym verwendet. Nach meinem Verständnis ist Data Wrangling eine spezielle Ausprägung von Data Preparation, die klar an den Fachanwender mit wenig IT-Know-how adressiert ist und die interaktive Arbeit an den Daten inklusive dem Verständnisgewinn für die Daten in den Vordergrund stellt.
Wie ist Data Wrangling von ETL abzugrenzen?
Auch klassisches ETL (Extract, Transform, Load) hat inhaltliche Überschneidungen mit Data Wrangling, jedoch gibt es deutliche Unterschiede bezüglich den Nutzern, den Daten und den Use-Cases.
So zielt der klassische ETL-Prozess mitsamt seinen typischen Tools wie Talend Open Studio, Oracle Data Integrator oder Microsoft SSIS klar auf den erfahrenen IT-Experten, mit Kenntnissen im Bereich SQL, Java, multidimensionaler Modellierung und Datenbanken und somit nicht auf den Fachanwender ab.
Die Daten unterscheiden sich dahingehend, dass beim klassischen ETL die Daten aus operativen Anwendungssysteme übernommen werden und daher stark strukturiert sind, beispielsweise wenn sie in einer Datenbank in dritter Normalform vorliegen. Beim Data Wrangling werden zusätzlich insbesondere semi-strukturierte Daten im Format JSON sowie unstrukturierte Daten (z.B. Texte, E-Mails) verarbeitet.
Auch unterschieden sich die typischen Use-Cases darin, dass ETL primär dem Ziel dient, ein zentralisiertes Enterprise Data Warehouse zu beladen, welches in der Regel als Single Point of Truth für Reporting- und Business Intelligence-Anwendungen dient. Stattdessen sind die Use-Cases für Data Wrangling auch eher vordergründig explorativer Art. Wenn beispielsweise ein kleines Fachteam an neuen der Einbindung neuer Datenquellen arbeitet oder Daten auf neuartige Weise verknüpft werden müssen. Denkbar ist auch, dass die Ergebnisse aus dem Data Wrangling-Prozess später im ETL-Prozess implementiert werden, so dass auch eine komplementäre Nutzung von Data Wrangling und ETL denkbar ist.
Produktvorstellung Trifacta
Bevor ich auf das Produkt eingehe, möchte ich zunächst auf das Unternehmen Trifacta und dessen Umfeld skizzieren.
Das Unternehmen Trifacta
Entstanden ist das Unternehmen aus dem gemeinsamen Forschungsprojekt „Data Wrangler“ der Universitäten in Berkeley und Stanford. Noch bevor das Forschungsprojekt beendet wurde, wurde im Oktober 2012 das Start-up Trifacta gegründet, um das entstandene Produkt kommerziell zu vertreiben.
Die Gründer sind Joseph M. Hellerstein, Professor an der UC Berkeley, sowie Jeffrey Heer und Sean Kandel, welche beide zu dieser Zeit in Stanford promoviert haben. Inhaltlich widmen sie sich den Themen Datenbanken und Datenvisualisierung.
Aktuell beschäftigt das Unternehmen ca. 170 Mitarbeiter und hat neben seinen Heimatstandort in San Fransisco auch Büros in London und Berlin eröffnet.
Das Produkt Trifacta Wrangler und seine Varianten
Der Wrangler ist eine Cloud-Anwendung, die in drei unterschiedlichen Varianten vertrieben wird.
Das Einstiegsprodukt ist der kostenlose Cloud-Dienst Wrangler. Er ist beschränkt auf 100 MB große Dateien in den Formaten CSV, JSON, TXT, Excel sowie Tableau Data Extract. Er wurde eine Zeit lang als hybride Desktop-Version veröffentlicht, welche aber aktuell nicht mehr unterstützt wird.
Etwas höher positioniert ist der kostenpflichtige Wrangler Pro, der sich an kleinere Teams richtet. Es handelt sich hierbei um eine Umgebung, die auf Amazon Web Services (AWS) gehostet wird. Die Pro-Variante hat dabei keinerlei Beschränkung der Dateigröße mehr und stellt Konnektivität zu allen gängigen relationalen Datenbanken sowie zu den Cloud-Plattformen AWS Redshift und AWS S3 her.
Die umfangreichte Variante nennt sich Wrangler Enterprise und zielt auf große Unternehmen ab. Installiert kann diese Variante sowohl auf On-Premise-Plattformen wie Cloudera oder Hortonworks als auch in Cloud-Umgebungen wie AWS, Google Cloud oder Microsoft Azure. Diese Version bietet als einzige eine umfangreiche Big Data-Unterstützung (HDFS, Hive, Spark, MongoDB,…) und bietet zusätzlich Konnektivität zu Microsoft Azure-Diensten.
Konzepte im Wrangler
Um zu verstehen, wie die Arbeitsabläufe im Wrangler organisiert sind, möchte ich kurz die grundlegenden Konzepte erläutern.
Datasets: Importiert man Dateien, beispielsweise im CSV-Format, in den Wrangler erhält man ein Imported Dataset. Ein solches Dataset stellt eine Referenz auf die Originaldatei dar. Die Originaldatei selbst wird nicht bearbeitet, sondern die Daten werden in einem sogenannten Flow manipuliert. Die bearbeiteten Daten lassen sich als Referenced Dataset festhalten und können an anderer Stelle weiterverarbeitet werden.
Recipes: Recipes stellen eine Sequenz von Bearbeitungsschritten an einem Dataset dar. Sie werden in natürlicher Sprache sowie einer speziellen Wrangle Language angezeigt. Recipes können exportiert werden. Erstellt werden sie in der Transformator Page unter Nutzung von automatisch erzeugten, kontextabhängigen Transformationsvorschlägen.
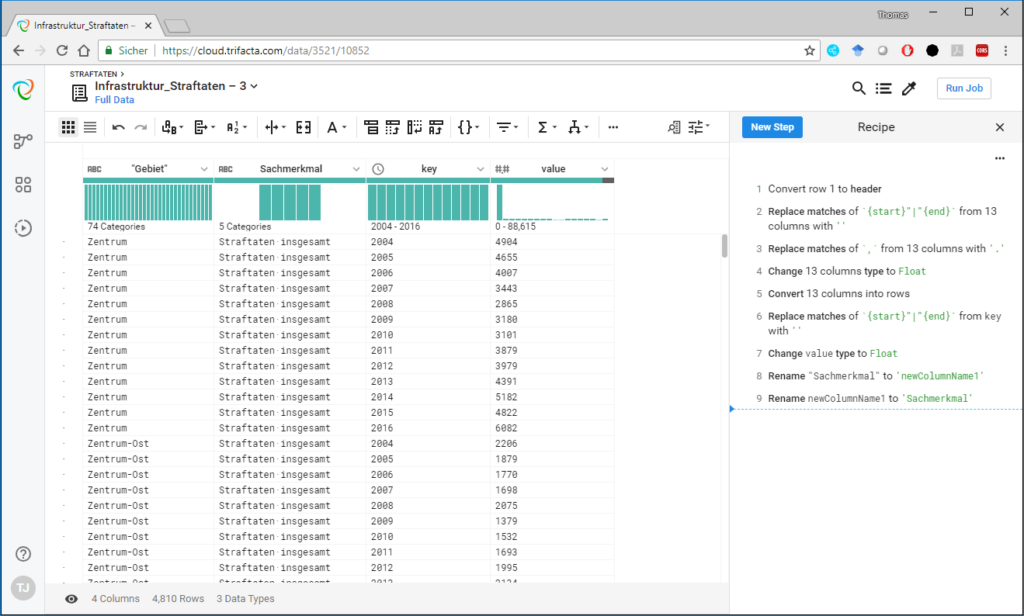
Abbildung 1 Transformator-Page mit Recipe
Flows: Flows sind Container, welche ein oder mehrere Datasets als Datengrundlage sowie Recipes und Outputs enthalten. Flows werden auf der dazugehörigen Page graphisch dargestellt.
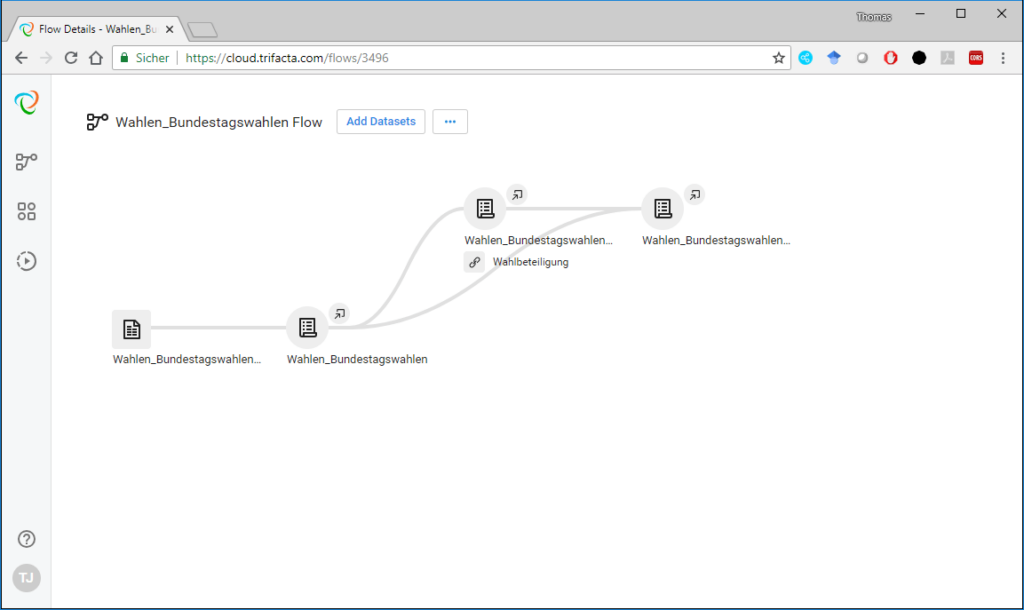
Abbildung 2 Darstellung eines Flows
Jobs: Jobs führen die Flows aus und ermöglichen es, nach den Durchlauf das Ergebnis als CSV-Datei herunterzuladen.
Der typische Workflow sieht so aus, dass man zunächst einige Datenquellen importiert und sich dann an den ersten Flow setzt. Am ersten Recipe testet man einige Bereinigungsschritte durch, ändert die Struktur durch Pivot oder Unpivot und fügt gegebenenfalls weitere Daten über den Join-Operator hinzu. Dann speichert man ein Zwischenergebnis als Referenced Dataset ab, führt den Job aus und arbeitet in einem zweiten Flow weiter.
Vergleichbare Produkte von Wettbewerbern
Die interessantesten Produkte der Wettbewerber sind für mich Paxata und Talend Data Preparation.
Während Paxata hinsichtlich Usability und Visualisierung Trifacta auf den ersten Blick mindestens ebenbürtig erscheint (siehe Video), ist das Data Preparation-Tool von Talend zwar nicht so „cutting-edge“ und intuitiv nutzbar, jedoch in einer kostenlosen Open-Source-Desktop-Version erhältlich, welche allerdings nur wenige Grundoperationen der Datenbereinigung enthält. Interessant hierbei ist allerdings die mögliche Weiterverwendung der erstellten Datenaufbereitungsprozesse in Talend Open Studio für Data Integration, mit der Möglichkeit den gesamten Datenaufbereitungs- und Integrationsprozess an einer Stelle zu automatisieren. Die kostenlose Version ist hierbei jedoch auch wieder stark eingeschränkt und kann nur CSV-Dateien verarbeiten.
Weitere Alternativen zum Data Wrangler wären die Nutzung von ETL-Tools oder einer Programmiersprache wie beispielsweise R. Beide Varianten bieten viele Möglichkeiten den Prozess individuell an besondere Anforderungen anzupassen. ETL-Tools bieten teilweise Unterstützung durch grafische Darstellung des Prozesses, bieten aber kaum Datenvisualisierungsmöglichkeiten. Nimmt man R als Programmiersprache, hat man den Vorteil, dass Analysten mitunter mit dieser Sprache vertraut sind und die tidyverse-Pakete viele Funktionalitäten für Data Preparation bieten. Jedoch ist die Nutzung auf die Interaktion zwischen Skript und Konsole beschränkt, so dass beispielsweise Histogramme immer einzeln aufgerufen werden müssen.
In der folgenden Tabelle habe ich die kostenlose Wrangler-Version mit anderen Tools verglichen, welche ebenfalls für Data Preparation in Betracht kommen können. Hierbei schneidet der Wrangler nur wegen der Begrenzung auf 100MB-Dateien in der Kategorie Formate und Datenmengen schlecht ab, für die Pro- und Enterpreise-Edition gilt dies selbstverständlich nicht. Talend Data Preparation sollte in der Free Desktop nur zusammen mit dem Datenintegrationstool verwendet werden, weil sonst selbst recht elementare Operationen wie Pivot/Unpivot nicht vorhanden sind.

Fazit
Meiner Meinung nach ist der Trifacta Wrangler ein interessantes Tool mit dem sich vergleichsweise erstaunlich umfangreiche Datentransformationenaufgaben ohne Programmieraufwand einfach über den Browser in der Cloud erledigen lassen.
Autor: Thomas, Datenbank-Entwickler bei der TIQ Solutions
Quellen und Literatur
Internet-Quellen:
Weldon, D. (2017). Slideshow 7 leading tools for data preparation.
Doering,B., Litzel, N. (2017). Was ist der Unterschied zwischen Data Wrangling und ETL?
Zheng, W. (2017) Data Wrangling Versus ETL: What’s the Difference?
Litzel, N. (2018) Was ist Data Preparation?
https://www.trifacta.com/data-wrangling/
https://www.trifacta.com/products/wrangler-editions/
Wissenschaftliche Artikel und Monografien:
Patil, M. M., & Hiremath, B. N. (2018). A Systematic Study of Data Wrangling.
Rattenbury, T., Hellerstein, J. M., Heer, J., Kandel, S., & Carreras, C. (2017). Principles of Data Wrangling: Practical Techniques for Data Preparation.
Boehmke, B. C. (2016). Data wrangling with R.



{kind=link}