
Data Science – ein Wort, über das man aktuell neben Big Data und künstliche Intelligenz immer wieder stolpert. Der technologische Fortschritt ermöglicht uns, riesige Datenmengen zu sammeln und diese möglichst gewinnbringend zu nutzen. Entwicklungen wie autonome Fahrzeuge, personalisierte Werbung, Social Bots, Smart Homes, Gesichtserkennung, Industrie 4.0 usw. lassen einen staunen und wundern, wo die Reise wohl hingeht.
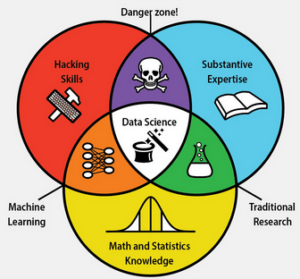
Bildquelle: Berkeley University
Im Zusammenhang mit diesen Entwicklungen fällt das Wort Data Scientist – Datenwissenschaftler. Jene Menschen, die zu diesen Entwicklungen beitragen. Aber was ist unter Data Science eigentlich genau zu verstehen? Der Name verrät, dass es irgendwas mit Daten und Wissenschaft zu tun haben muss. Erste Erwähnungen des Begriffs Data Science können auf die 60er Jahren zurückdatiert werden, damals als Alternativbegriff zur Informatik. In den 70er Jahren fiel der Begriff zuweilen im Zusammenhang mit der zeitgenössischen Datenverarbeitung. In den 90er Jahren galt Data Science als modernere Bezeichnung für Statistik. Seit 2001 ist Data Science eine eigenständige Berufsbezeichnung. Heute versteht man Data Science als eine Schnittmenge von Informatik, Mathematik und spezifischen Domänenwissen. Die Grenzen sind jedoch immer noch strittig und die erforderlichen Fähigkeiten nicht klar definiert und unterliegen dem rasanten Fortschritt an Methoden und Technik auf diesem Gebiet. Zudem sorgen neue Berufsbezeichnungen wie Data Analyst und Data Engineer für weitere Verwirrung.
Aber was tut der Datenwissenschaftler nun genau und was daran ist eigentlich Wissenschaft?
Ganz grundsätzlich beschäftigt sich der Data Scientist mit der Generierung von Wissen aus Daten unter Anwendung von mathematischen Methoden und Modellen. Dabei erinnert vor allem seine Arbeitsweise an die in der wissenschaftlichen Praxis, in der man eine Problemstellung mit Hilfe geeigneter Methoden bearbeitet und gegebenenfalls löst.
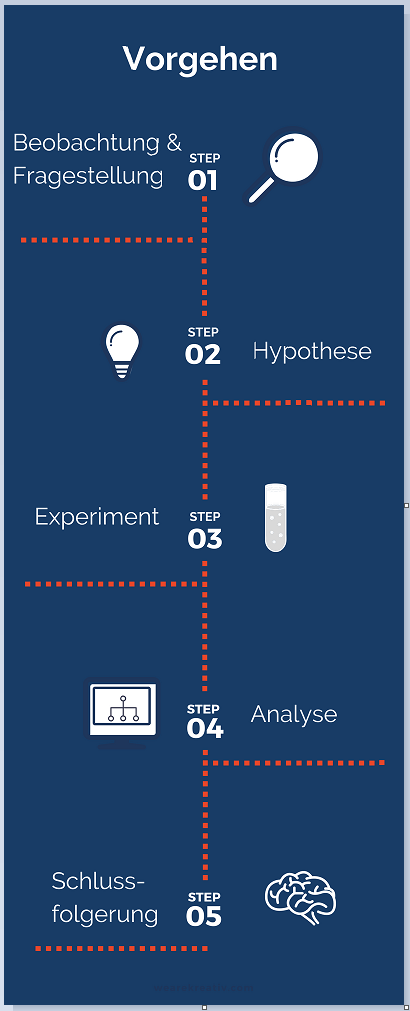
Dieser Prozess kann ganz grob in die folgenden Phasen unterteilt werden. Ausgehend von einer Beobachtung, entwickelt man eine übergeordnete Fragestellung. Unter Berücksichtigung des aktuellen Wissensstandes stellt man folgend eine Hypothese auf. Diese Hypothese versucht man unter Anwendung geeigneter Methoden in einem Experiment statistisch signifikant zu bestätigen oder zu widerlegen. Das neu generierte Wissen produziert wiederum neue zu überprüfende Hypothesen. Übergeordnet wird dabei besonders Wert darauf gelegt, die neuen Erkenntnisse kritisch zu betrachten und auf ihre Gültigkeit hin einzugrenzen und als finales Ergebnis in den aktuellen Wissensstand einzuordnen.
Wie sieht das nun im Alltag des Data Scientisten aus?
Im Folgendem ein Erklärungsversuch am Beispiel einer Industrie 4.0 Anwendung: Im Idealfall erhält der Data Scientist einen Berg an Daten und eine konkrete Fragestellung. Beispielsweise, ob mit Hilfe von den Daten, die durch verschiedene Sensoren in einem Produktionsprozess aufgezeichnet werden, der Zeitpunkt eines Maschinenausfalls vorhergesagt werden kann.
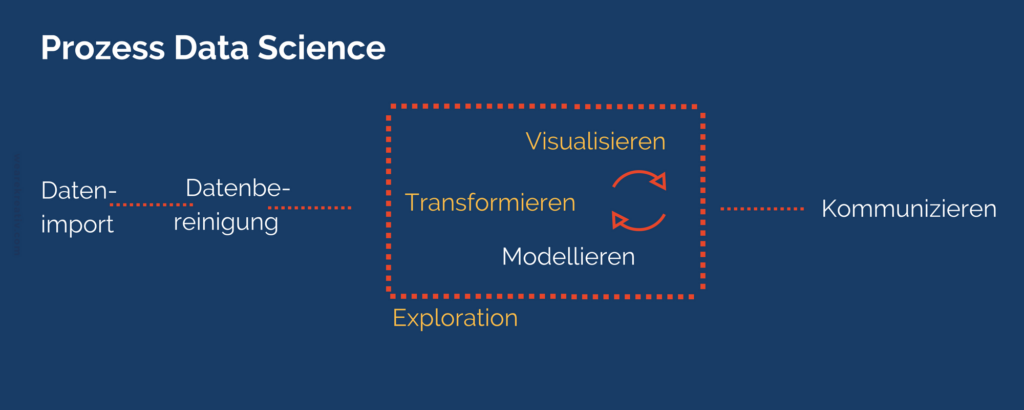
angelehnt an Wickham & Grolemund
Sind bereits Daten vorhanden, erfolgt zunächst die Bestandsaufnahme und Recherche. Die Daten werden dann in eine spezielle Software importiert (beispielsweise R oder Python) und in einem oftmals sehr aufwändigen Prozess aufgeräumt und nutzbar gemacht.
Im Anschluss erfolgt ein iterativer Prozess aus Datentransformation, Visualisierung und Modellierung. Dabei interessieren dem Data Scientist zum einen die Zusammensetzung und der Inhalt der Daten. Was enthält der Datensatz, wie sind die Daten verteilt und gibt es bestimmte Auffälligkeiten oder Muster in den Daten? Das sind einige von vielen möglichen Fragestellungen. Dazu kann er aus einem riesigen und ständig wachsenden Pool an Methoden der Datenexploration (z.B. Visualisierung) und des Data Minings und später an mathematischen Modellen die geeignetsten Werkzeuge wählen. Zum anderen eignet sich der Data Scientist fachspezifisches Wissen der Anwendungsdomäne an. Mit Hilfe dieses Domänenwissens und den Erkenntnissen der Datenexploration stellt er Hypothesen darüber auf, wie die Daten am besten zusammenzufassen sind (welche Features) und welches mathematische Modell am geeignetsten zur Lösung der Fragestellung wären. In unzähligen Experimenten wird untersucht, welche Features bewährte sind, welches Modell die besten Vorhersagen macht, und welche Modellparameter zu verwenden sind.
Am Ende einer langen Reise hat der Data Scientist ein mathematisches Modell in der Hand. In diesem Fall, könnte man dann dem Modell neue, entsprechend vorbereitete Sensordaten geben und es würde einem sagen, ob eine Maschine in Zukunft ausfallen wird. Diese Information kann u.a. genutzt werden, um einen unnötigen Produktionsausfall zu vermeiden, logistische Abläufe zu verkürzen und dem Wartungsmechaniker das Leben zu erleichtern. Dabei besteht auch hier die dringende Notwendigkeit die Grenzen des Modells zu definieren und zu kommunizieren. Denn am Ende ersetzt das Modell nicht das fachliche Individuum, sondern soll es in seinen Entscheidungen unterstützen.
Autorin: Jule, Data Scientist – TIQ Solutions GmbH



{kind=link}