
Maschinelle Lernverfahren (Machine Learning / ML) sind ein mächtiges Werkzeug, um aus Erfahrungen zu lernen und zukünftige Entscheidungen datenbasiert zu treffen. Bei der Umsetzung eines solchen ML-Ansatzes führen verschiedene Wege zum Ziel. Das Spektrum reicht dabei von Speziallösungen, die auf konkrete Anwendungsfälle zugeschnitten sind, bis hin zu frei programmierbaren ML-Umgebungen, die sich an nahezu jede Aufgabenstellung anpassen lassen. So gibt es Dienste zur automatischen Spracherkennung in Audiodaten oder zur Identifikation von Gesichtern in Bildern. Aus Anwendersicht ist bei diesen Diensten nur bedingt erkennbar, dass hinter den Kulissen vortrainierte Modelle zum Einsatz kommen. Ein Vorteil ist, dass diese Lösungen relativ einfach einzubinden sind und ohne ML-Vorkenntnisse eingesetzt werden können. Vertieftes Know-how im Bereich Programmierung und Data Science sind hingegen am anderen Ende des Lösungsspektrums nötig. So ist es mit Tools und Frameworks wie Python, R und Tensorflow möglich, individuelle ML-Architekturen und komplexe Verarbeitungsprozesse zu implementieren. Der Preis dieser Freiheit ist aber oftmals die Nutzerfreundlichkeit und somit die Einsetzbarkeit bei Endanwendern.
Ein Mittelweg zwischen diesen beiden Ansätzen bilden die sogenannten Guided-Analytics-Tools, bei denen die Umsetzung und die Steuerung des ML-Prozesses in einer grafischen Benutzeroberfläche geschieht. Dabei werden Workflows durch einfaches Zusammenklicken und Verbinden nach dem Baukastenprinzip erstellt. Der Berechnungsprozess wird grafisch dargestellt und gewährt so eine Gesamtsicht auf die Datenflüsse sowie die ausgeführten Verarbeitungsschritte. Ausgewählte Parameter erlauben es, ganz ohne Programmierkenntnisse, die Funktionsweise einzelner vorkonfigurierter Module zu beeinflussen. Für komplexere Aufgaben stehen meist spezielle Skripting-Operatoren bereit, welche das Schreiben und Ausführen von Code ermöglichen. Mit einem einzigen Tool lassen sich so die Anforderungen verschiedener Nutzergruppen erfüllen.
Azure Machine Learning Studio
Ein Vertreter dieses Typs von ML-Anwendungen ist das Azure Machine Learning Studio (AMLS) von Microsoft, was hier kurz vorgestellt werden soll. Wie der Name nahelegt, wird dieses Tool als Dienst innerhalb der Azure-Cloud-Computing-Plattform bereitgestellt. Um ihn nutzen zu können, muss zunächst mit einem entsprechenden Account im Azure-Portal ein AMLS-Arbeitsbereich erstellt werden. Danach loggt man sich mit einem Browser https://studio.azureml.net in die AMLS-Oberfläche (siehe Abbildung) ein und kann dort projektbasiert erste ML-Experimente anlegen. Eine Besonderheit hierbei ist, dass diese Workflows an Andere freigegeben werden können und somit ein gemeinsames Bearbeiten möglich ist. Eine große Auswahl an Demodaten und Beispielexperimenten erleichtert hier die ersten Schritte. Über die Oberfläche können ebenso lokale Daten hochgeladen und in bestehende Experimente eingebunden werden. In einem Experiment wird der konkrete ML-Workflow mit seinen Modulen (Verarbeitungsschritten) und Kanten (Datenflüsse) per Drag-and-Drop aus einer am Rand befindlichen Menüleiste zusammengestellt. Durch schrittweises Ausführen der Module gelangt man so von einer Ausgangsdatenmenge zu einem Prognosemodell. Fertig trainierte Modelle lassen sich als Web-Services bereitstellen und innerhalb der Azure-Umgebung in andere Anwendungen und Dienste einbinden.
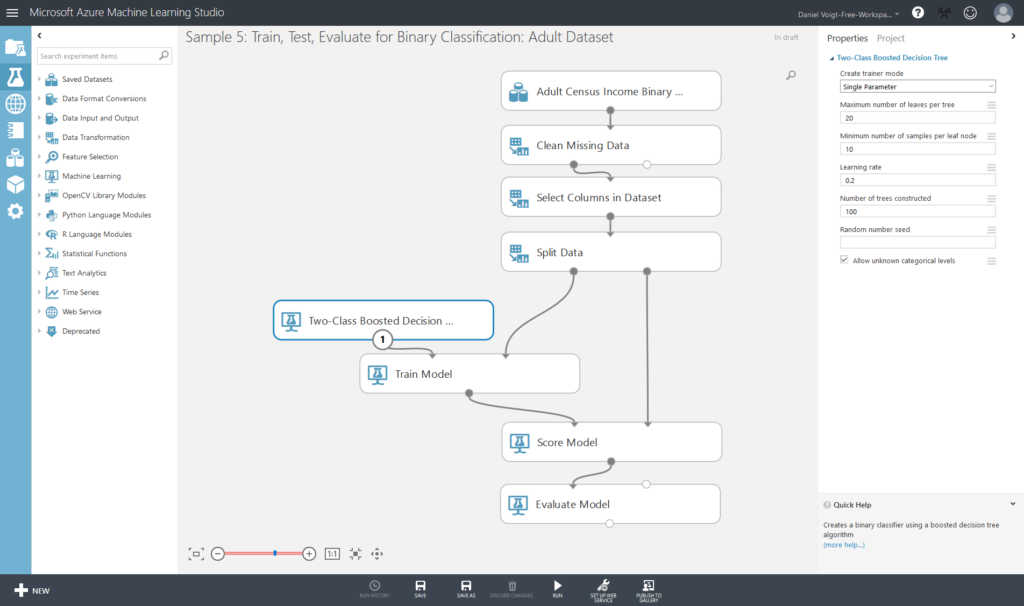
(grafische Benutzeroberfläche des Azure Machine Learning Studios)
Data Science mit AMLS
Wie in einem vorherigen Blogbeitrag erläutert, besteht der typische Data-Science-Prozess grob aus sechs Schritten, die teilweise iterativ durchlaufen werden: Import, Bereinigung, Transformation, Visualisierung, Modellierung und Kommunikation. Um eine bessere Vorstellung vom Funktionsumfang des AMLS zu bekommen, wollen wir uns nun für diese Schritte einige ausgewählte Module anschauen.
Datenimport
Unter dem Menüpunkt „Data Input and Output“ findet sich das entsprechende Modul zum Einlesen von Daten. Aus einer Reihe von Datenquellen lassen sich hier strukturierte (sprich tabellenförmige) Daten importieren. Als mögliche Formate kommen hierbei CSV, TSV, ARFF und SVMLight zum Einsatz, die entweder via HTTP von einer Web-URL oder direkt aus einem Azure Blob Storage gelesen werden können. Daneben gibt es auch die Möglichkeit, auf Datenbanken wie Azure SQL Database, Table und Cosmos DB sowie Hadoop zuzugreifen.
Datenvorbereitung
Nachdem die Daten importiert wurden, geht es nun im nächsten Schritt an ihre Bereinigung und Transformation. Hierfür stehen unter „Data Transformation“ verschiedene Module bereit. Ein häufig auftretendes Problem sind beispielsweise fehlende Daten, für deren Korrektur das Modul „Clean Missing Data“ mit seinen verschiedenen Methoden der Imputation geeignet ist. Ebenso lassen sich doppelte Datensätze („Remove Duplicate Rows“) und Wertüberschreitungen („Clip Values“) bereinigen. Mit anderen Modulen lassen sich Datenmengen kombinieren („Add Columns / Rows“, „Join Data“), Wertebereiche transformieren („Normalize Data“, „Group Data into Bins“) sowie ihre Repräsentation verändern („Convert to Indicator Values“, „Principal Component Analysis“). Mit diesen Bausteinen lässt sich bereits eine Menge an praxisrelevanten Standardaufgaben lösen. Sollte es dennoch etwas aufwändiger werden, kann man zusätzlich auf spezielle SQL/R/Python-Operatoren zurückgreifen.
Modellbildung
Die transformierten Daten und berechneten Merkmalsbeschreibungen bilden im nächsten Schritt die Grundlage des ML-Prozesses. Hierfür werden die Daten zunächst in eine Trainings- und Testmenge aufgeteilt, mit denen das Modell nachfolgend angepasst und evaluiert wird. Die für diesen Zweck geeigneten Module („Partition and Sample“, „Split Data“) finden sich im Untermenü „Sample and Split“. Nun kommen wir zum Herzstück des AMLS – den ML-Modulen, mit denen sich die mathematischen Modelle aufbauen lassen (zu finden im Menü „Machine Learning / Initialize Model“). Hierbei muss zunächst nach der Zielstellung des zu trainierenden Modells unterschieden werden. Eine einfache Clusteranalyse (Gruppierung von ähnlichen Daten) lässt sich mit dem „K-Means“-Modul ausführen, eine Anomaliedetektion (Erkennung von Ausreißern) mit „One-Class SVM“ bzw. mit „PCA-Based Anomaly Detection“. Zur Zuordnung von Datensätzen zu bestimmten Kategorien stehen unter „Classification“ verschiedene ML-Verfahren zur Auswahl (u.a. Entscheidungsbäume, logistische Regression, neuronale Netze). Analog finden sich unter „Regression“ die Module zur Prognose von numerischen Werten. Nachdem hier das passende Modell ausgewählt wurde, kann durch Verknüpfung mit den unter „Train“ zu findenden Operatoren der Trainingsprozess gestartet werden. Die Güte des resultierenden Modells kann dann mithilfe von „Score Model“ und „Evaluate Model“ bewertet werden. Verschiedene Metriken können hierbei herangezogen werden (z.B. AUC, Precision, Recall), um letztlich die optimale Modellauswahl treffen zu können.
Grenzen von AMLS
Zwei Bestandteile des Data-Science-Prozesses wurden bisher noch nicht betrachtet: Visualisierung und Kommunikation. Dies geschieht aus gutem Grund, denn genau hier liegen Schwachstellen von AMLS. Möglichkeiten zur Visualisierung von Daten und Zwischenergebnissen sind nur sehr rudimentär ausgeprägt (bzw. in Untermenüs versteckt). Außer einfachen Histogrammen und Scatterplots wird hier wenig angeboten, um die Datenexploration zu unterstützen. Daten und Ergebnisse können zwar in einem parallel zu öffnenden Jupyter-Notebook eingelesen und dort grafisch dargestellt werden. Aber dieser Bruch im visuellen Bedienkonzept von AMLS ist eigentlich unnötig.
Ebenso mager steht es um Möglichkeiten zur Kommunikation von Modellen und den zugrundeliegenden Workflows. Natürlich können die Module und Experimente mit erläuternden Kommentaren versehen werden, aber auch hier ist eine brauchbare Lösung nur über den Umweg externer Tools zu haben. Dort lassen sich dann die Ergebnisse in erklärenden und dokumentierenden Kontext einbetten. In Form von Reports und Präsentationen wird so die Grundlage zur Interpretation, zum Verständnis und letztlich zur Akzeptanz des ML-Modells geschaffen.
Fazit
Geht man allerdings von einem enger gefassten Data-Science-Verständnis aus und möchte schnell standardisierte Prognosemodelle bereitstellen, so ist das AMLS ein nützliches Tool, das auch im praktischen Einsatz denkbar ist. Durch die einfache Bedien- und Anpassbarkeit lassen sich auch von ML-Neueinsteigern in kurzer Zeit brauchbare Modelle erzeugen und Analyseideen intuitiv ausprobieren. Auf der einen Seite bekommen Endanwender (im Wortsinn) ein besseres Bild vom stattfindenden ML-Prozess und können ein besseres Verständnis der spezifischen Herangehensweisen und Herausforderungen aufbauen. Auf der anderen Seite haben Data Scientists (innerhalb eines gewissen Rahmens) die Möglichkeit zur schnellen Anpassung der Funktionalität. In einem ML-Projekt kann das AMLS daher ein sinnvolles Bindeglied zwischen allen Projektbeteiligten sein und dabei helfen, aus Daten relevante Informationen zu gewinnen und nutzbar zu machen.
Autor: Daniel, Senior Consultant Data Science – TIQ Solutions GmbH


{kind=link}